Geometric Features Informed Multi-Person Human-Object Interaction Recognition in Videos
Tanqiu Qiao, Qianhui Men, Frederick W. B. Li, Yoshiki Kubotani, Shigeo Morishima and Hubert P. H. Shum
Proceedings of the 2022 European Conference on Computer Vision (ECCV), 2022
H5-Index: 262# Core A* Conference‡ Citation: 35#
Abstract
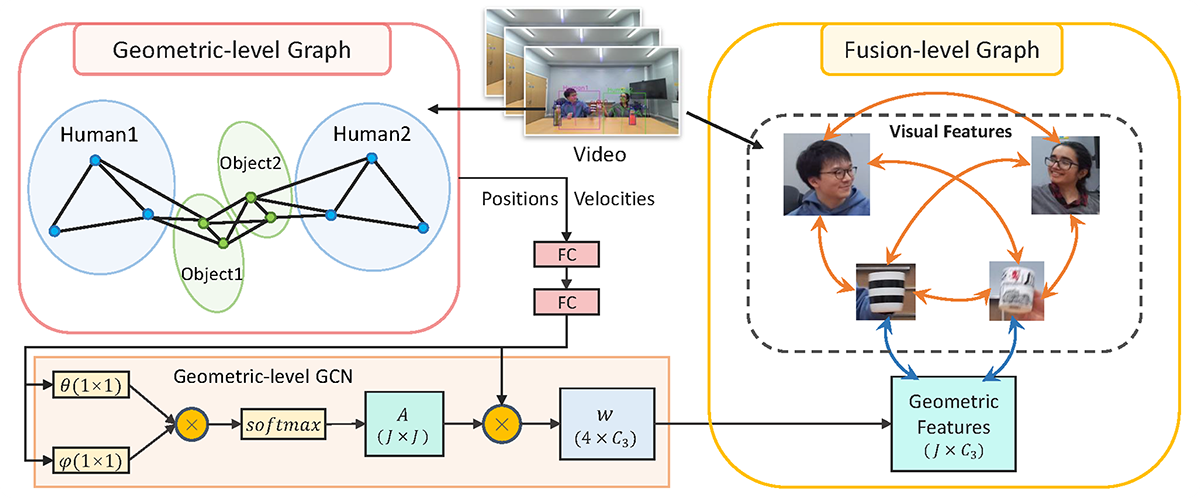
Human-Object Interaction (HOI) recognition in videos is important for analysing human activity. Most existing work focusing on visual features usually suffer from occlusion in the real-world scenarios. Such a problem will be further complicated when multiple people and objects are involved in HOIs. Consider that geometric features such as human pose and object position provide meaningful information to understand HOIs, we argue to combine the benefits of both visual and geometric features in HOI recognition, and propose a novel Two-level Geometric feature-informed Graph Convolutional Network (2G-GCN). The geometric-level graph models the interdependency between geometric features of humans and objects, while the fusion-level graph further fuses them with visual features of humans and objects. To demonstrate the novelty and effectiveness of our method in challenging scenarios, we propose a new multi-person HOI dataset (MPHOI-72). Extensive experiments on MPHOI-72 (multi-person HOI), CAD-120 (single-human HOI) and Bimanual Actions (two-hand HOI) datasets demonstrate our superior performance compared to state-of-the-arts.