Post-Doctoral Research Associate Postion Available
We are recruiting a Post-Doctoral Research Associate in Computer Vision and Artificial Intelligence. Deadline: 17th May 2026. More information here.
TFDM: Time-Variant Frequency-Based Point Cloud Diffusion with State Space Model
Jiaxu Liu, Li Li, Hubert P. H. Shum and Toby P. Breckon
Proceedings of the 2026 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop (CVPRW), 2026
Abstract
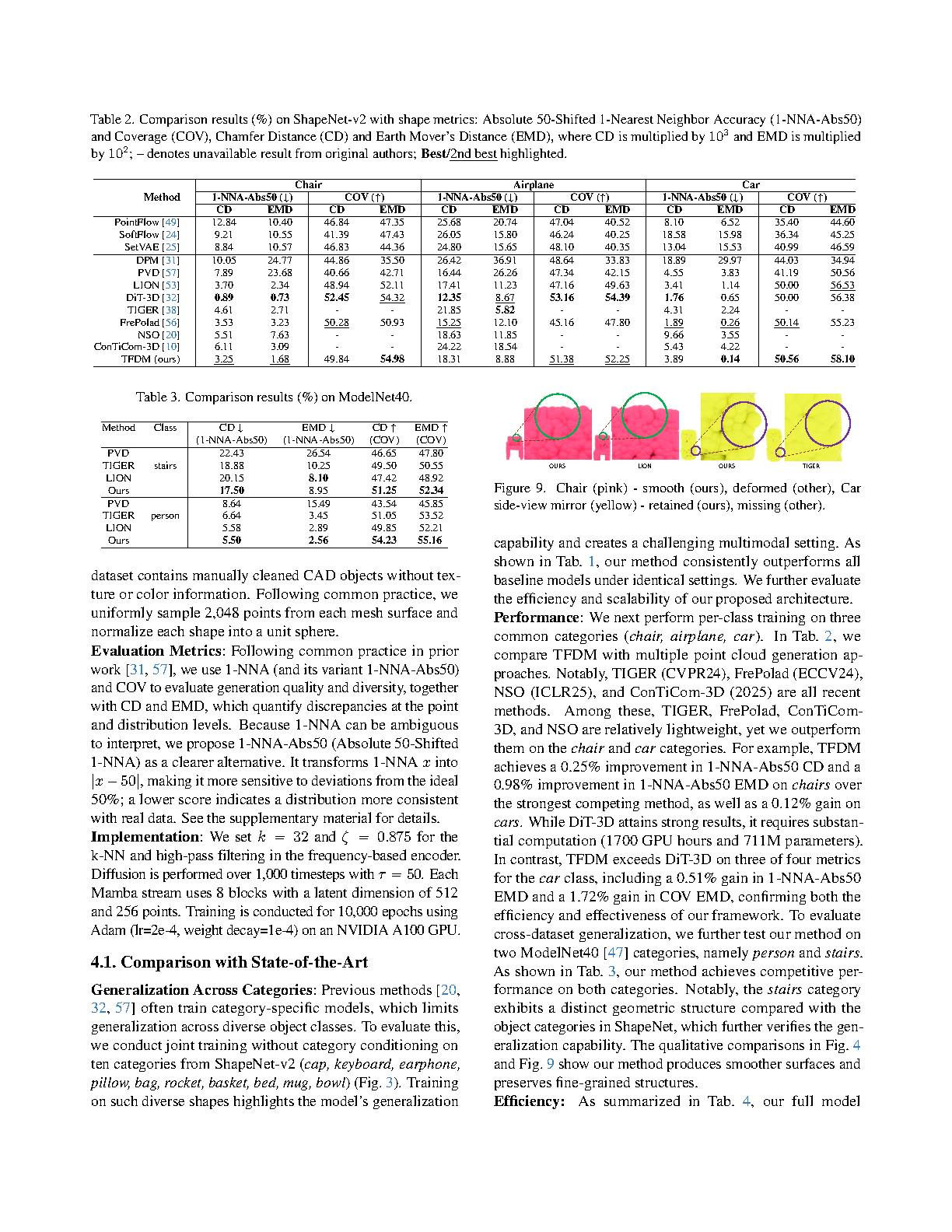
Diffusion models currently demonstrate impressive performance over various generative tasks. Recent work on image diffusion highlights the strong capabilities of Mamba (state space models) due to its efficient handling of long-range dependencies and sequential data modeling. Unfortunately, joint consideration of state space models with 3D point cloud generation remains limited. To harness the powerful capabilities of the Mamba model for 3D point cloud generation, we propose a novel diffusion framework containing dual latent Mamba block (DM-Block) and a time-variant frequency encoder (TF-Encoder). The DM-Block apply a space-filling curve to reorder points into sequences suitable for Mamba state-space modeling, while operating in a latent space to mitigate the computational overhead that arises from direct 3D data processing. Meanwhile, the TF-Encoder takes advantage of the ability of the diffusion model to refine fine details in later recovery stages by prioritizing key points within the U-Net architecture. This frequency-based mechanism ensures enhanced detail quality in the final stages of generation. Experimental results on the ShapeNet-v2 dataset demonstrate that our method achieves state-of-the-art performance (ShapeNet-v2: 0.14% on 1-NNA-Abs50 EMD and 57.90% on COV EMD) on certain metrics for specific categories while reducing computational parameters and inference time by up to 10X and 9X, respectively. The source code is included in the supplementary material and will be released.