Unaligned 2D to 3D Translation with Conditional Vector-Quantized Code Diffusion using Transformers
Abril Corona-Figueroa, Sam Bond-Taylor, Neelanjan Bhowmik, Yona Falinie A. Gaus, Toby P. Breckon, Hubert P. H. Shum and Chris G. Willcocks
Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023
H5-Index: 256# Core A* Conference‡ Citation: 14#
Abstract
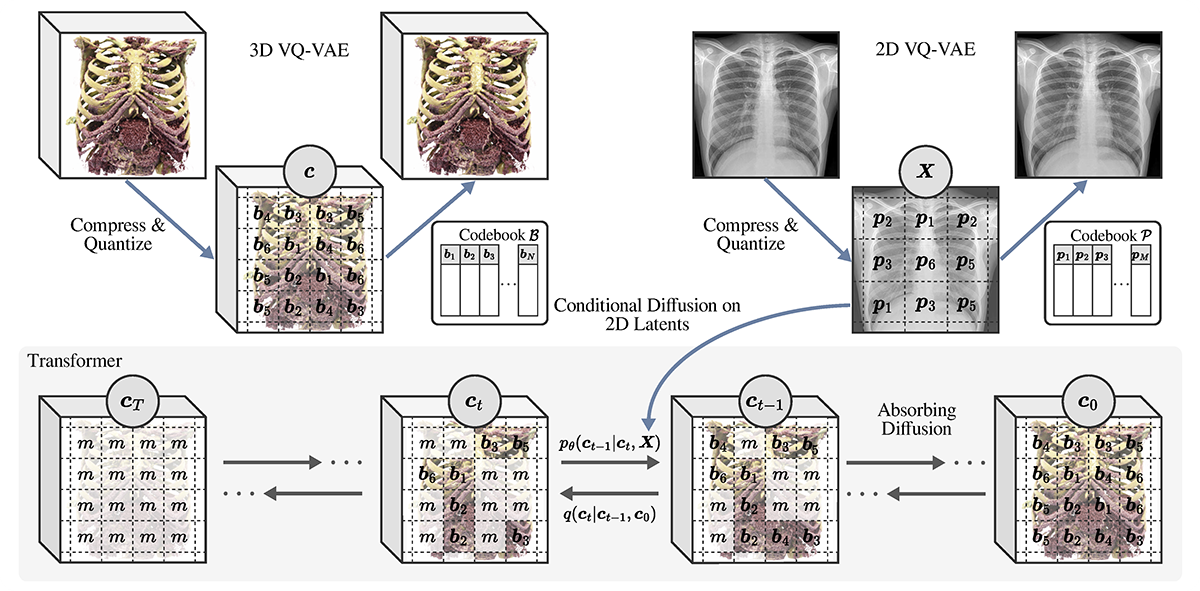
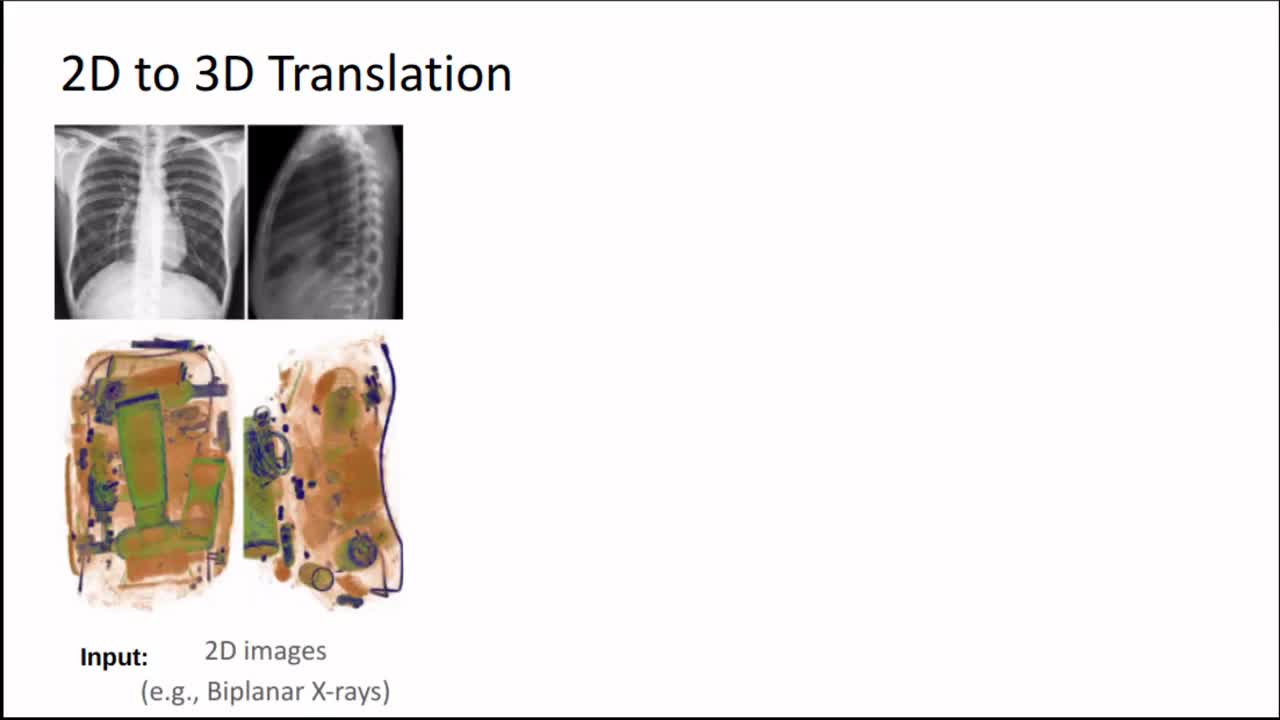
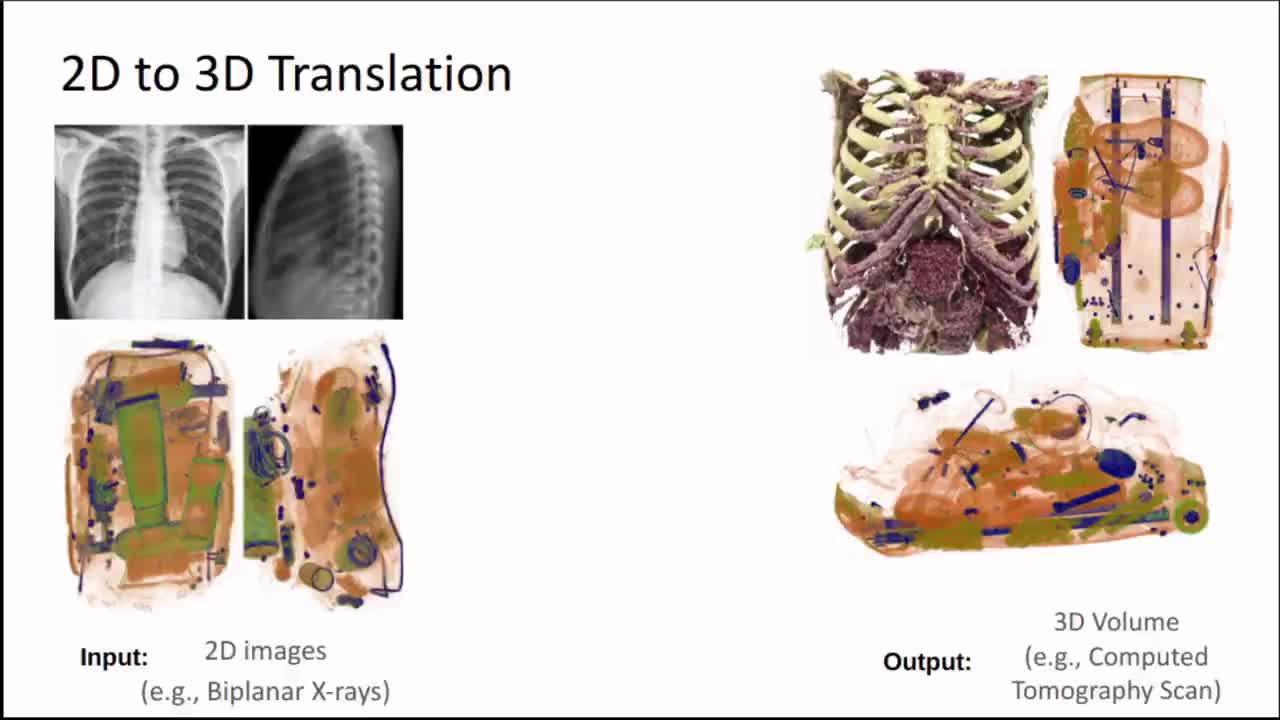
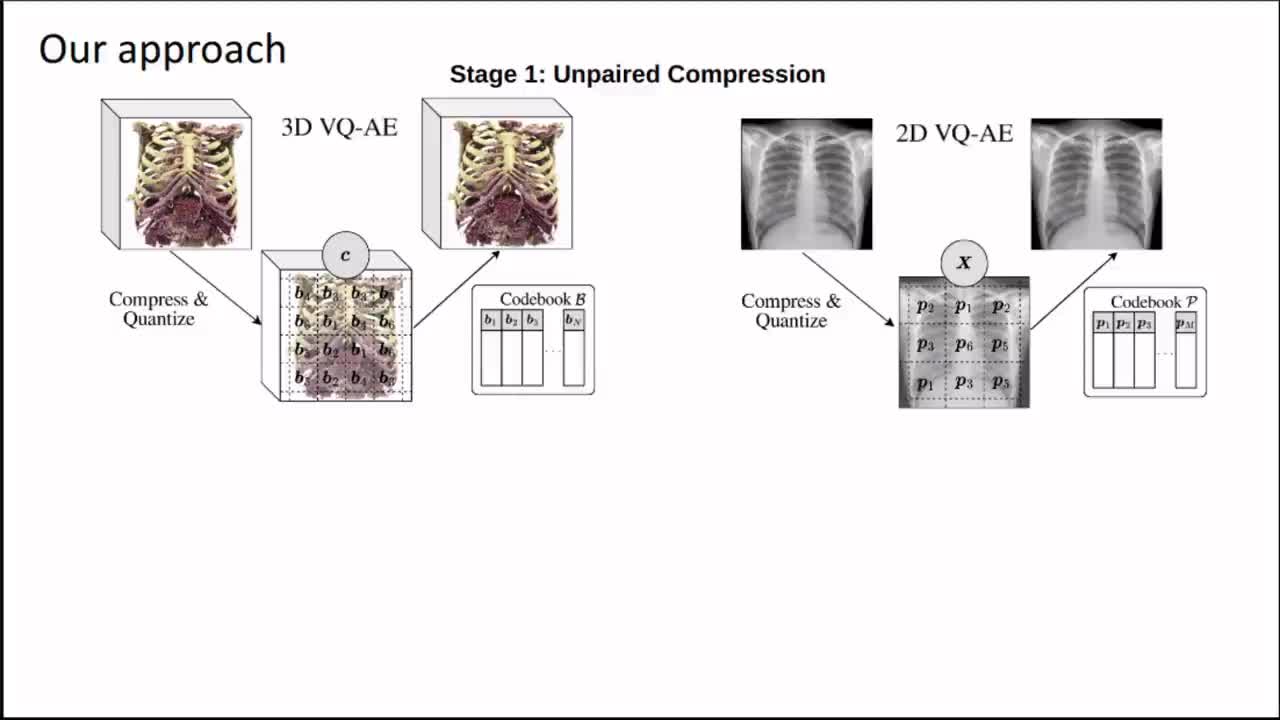
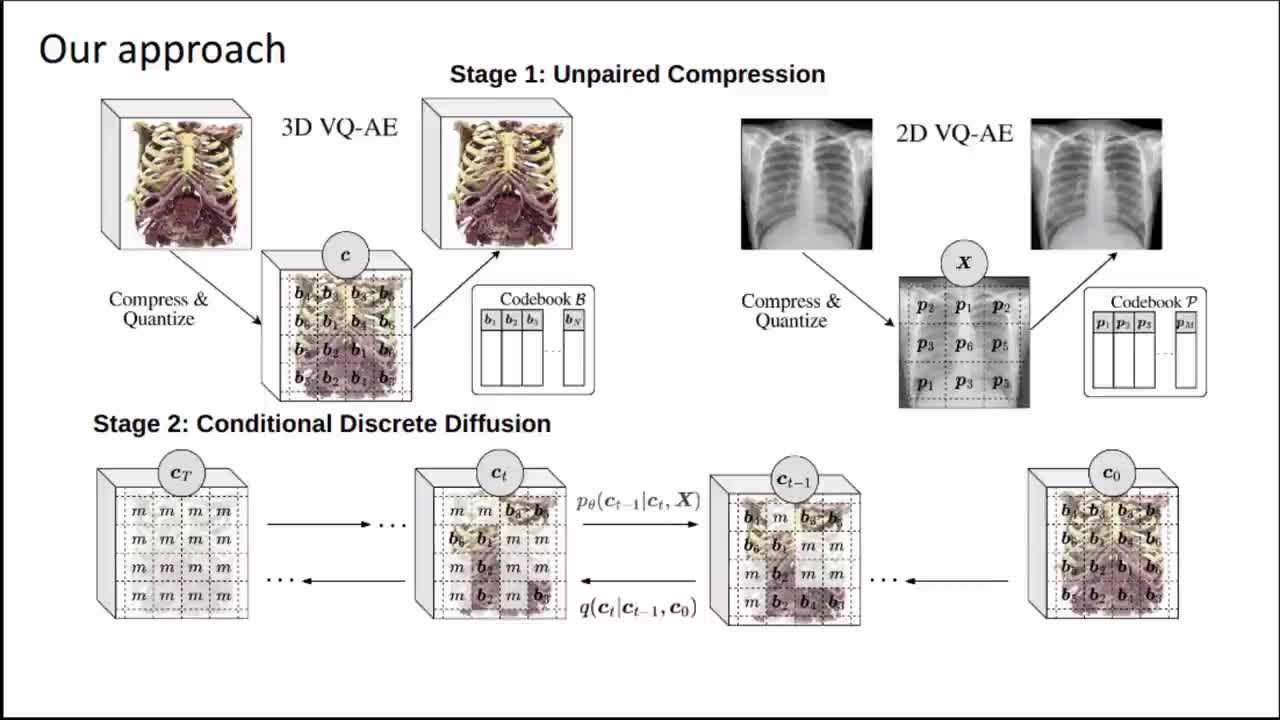
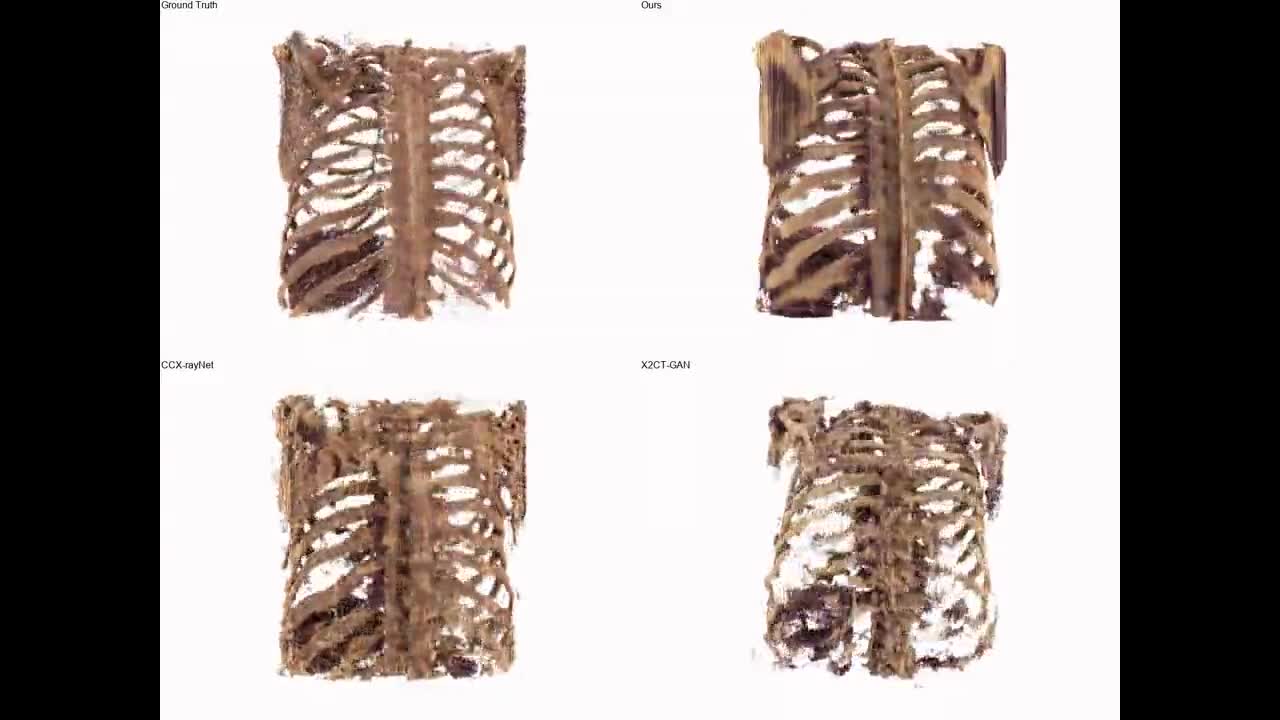
Generating 3D images of complex objects conditionally from a few 2D views is a difficult synthesis problem, compounded by issues such as domain gap and geometric misalignment. For instance, a unified framework such as Generative Adversarial Networks cannot achieve this unless they explicitly define both a domain-invariant and geometric-invariant joint latent distribution, whereas Neural Radiance Fields are generally unable to handle both issues as they optimize at the pixel level. By contrast, we propose a simple and novel 2D to 3D synthesis approach based on conditional diffusion with vector-quantized codes. Operating in an information-rich code space enables highresolution 3D synthesis via full-coverage attention across the views. Specifically, we generate the 3D codes, e.g. for CT images, conditional on previously generated 3D codes and the entire codebook of two 2D views (e.g. 2D X-rays). Qualitative and quantitative results demonstrate state-ofthe- art performance over specialized methods across varied evaluation criteria, including fidelity metrics such as density and coverage and distortion metrics for two datasets of complex volumetric imagery found in real-world scenarios.




















YouTube
Cite This Research
Supporting Grants

EPSRC Digital Health Hub Pilot Scheme (Ref: EP/X031012/1): £4.17 million, Co-Investigator (PI: Prof. Abigail Durrant)
Received from The Engineering and Physical Sciences Research Council, UK, 2023-2027
Project Page