Action Recognition from Arbitrary Views Using Transferable Dictionary Learning
Jingtian Zhang, Hubert P. H. Shum, Jungong Han and Ling Shao
IEEE Transactions on Image Processing (TIP), 2018
REF 2021 Submitted Output Impact Factor: 13.7† Top 10% Journal in Computer Science, Artificial Intelligence† Citation: 72#
Abstract
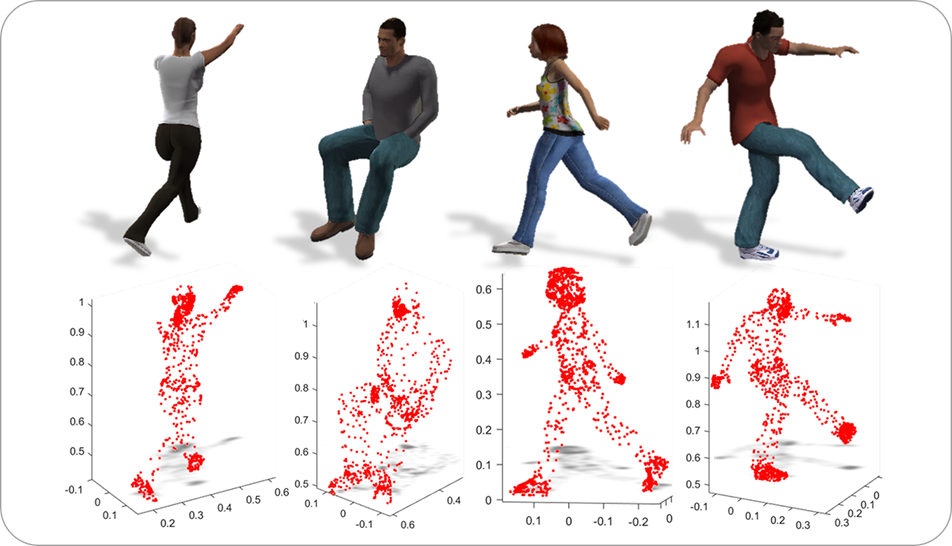
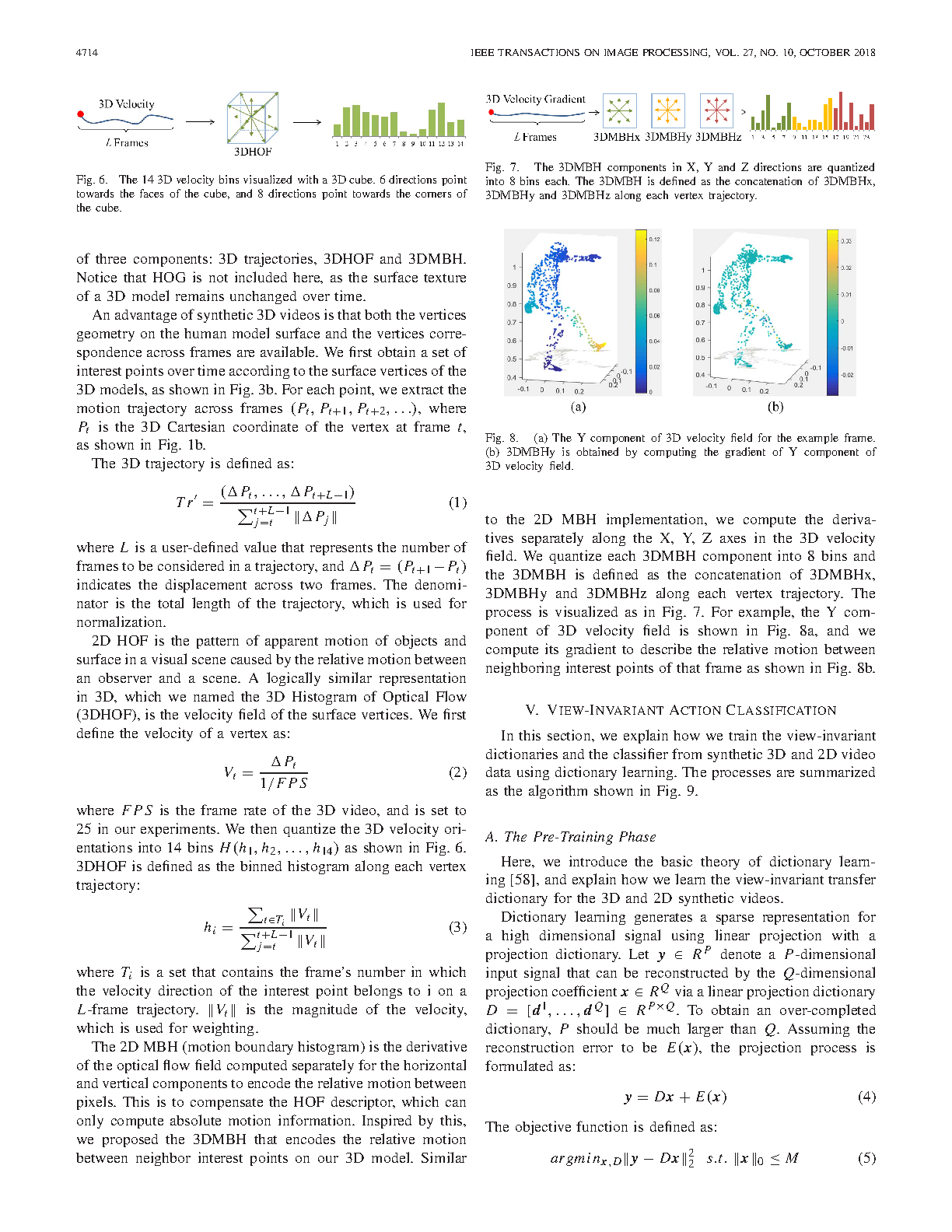
Human action recognition is crucial to many practical applications, ranging from human-computer interaction to video surveillance. Most approaches either recognize the human action from a fixed view or require the knowledge of view angle, which is usually not available in practical applications. In this paper, we propose a novel end-to-end framework to jointly learn a view-invariance transfer dictionary and a view-invariant classifier. The result of the process is a dictionary that can project real-world 2D video into a view-invariant sparse representation, and a classifier to recognize actions with an arbitrary view. The main feature of our algorithm is the use of synthetic data to extract view-invariance between 3D and 2D videos during the pre-training phase. This guarantees the availability of training data, and removes the hassle of obtaining real-world videos in specific viewing angles. Additionally, for better describing the actions in 3D videos, we introduce a new feature set called the3D dense trajectories to effectively encode extracted trajectory information on 3D videos. Experimental results on the IXMAS, N-UCLA, i3DPost and UWA3DII data sets show improvements over existing algorithms.









Cite This Research
Supporting Grants

Received from Northumbria University, UK, 2015-2018
Project Page

EPSRC First Grant Scheme (Ref: EP/M002632/1): £123,819, Principal Investigator
Received from The Engineering and Physical Sciences Research Council, UK, 2014-2016
Project Page