Focalized Contrastive View-Invariant Learning for Self-Supervised Skeleton-Based Action Recognition
Qianhui Men, Edmond S. L. Ho, Hubert P. H. Shum and Howard Leung
Neurocomputing, 2023
Impact Factor: 6.5† Top 25% Journal in Computer Science, Artificial Intelligence† Citation: 33#
Abstract
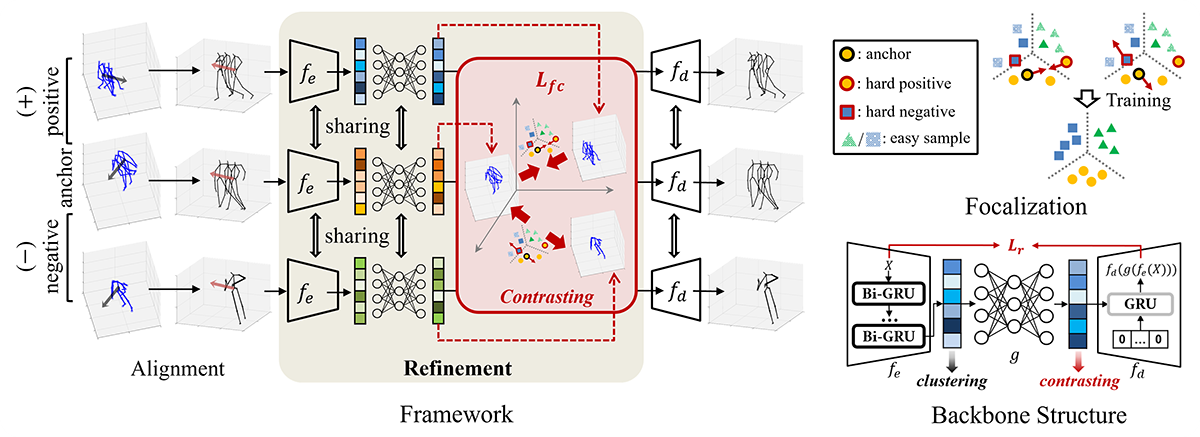
Learning view-invariant representation is a key to improving feature discrimination power for skeleton-based action recognition. Existing approaches cannot effectively remove the impact of viewpoint due to the implicit view-dependent representations. In this work, we propose a self-supervised framework called Focalized Contrastive View-invariant Learning (FoCoViL), which significantly suppresses the view-specific information on the representation space where the viewpoints are coarsely aligned. By maximizing mutual information with an effective contrastive loss between multi-view sample pairs, FoCoViL associates actions with common view-invariant properties and simultaneously separates the dissimilar ones. We further propose an adaptive focalization method based on pairwise similarity to enhance contrastive learning for a clearer cluster boundary in the learned space. Different from many existing self-supervised representation learning work that rely heavily on supervised classifiers, FoCoViL performs well on both unsupervised and supervised classifiers with superior recognition performance. Extensive experiments also show that the proposed contrastive-based focalization generates a more discriminative latent representation.









