360 Depth Estimation in the Wild - The Depth360 Dataset and the SegFuse Network
Qi Feng, Hubert P. H. Shum and Shigeo Morishima
Proceedings of the 2022 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), 2022
H5-Index: 52# Core A* Conference‡ Citation: 32#
Abstract
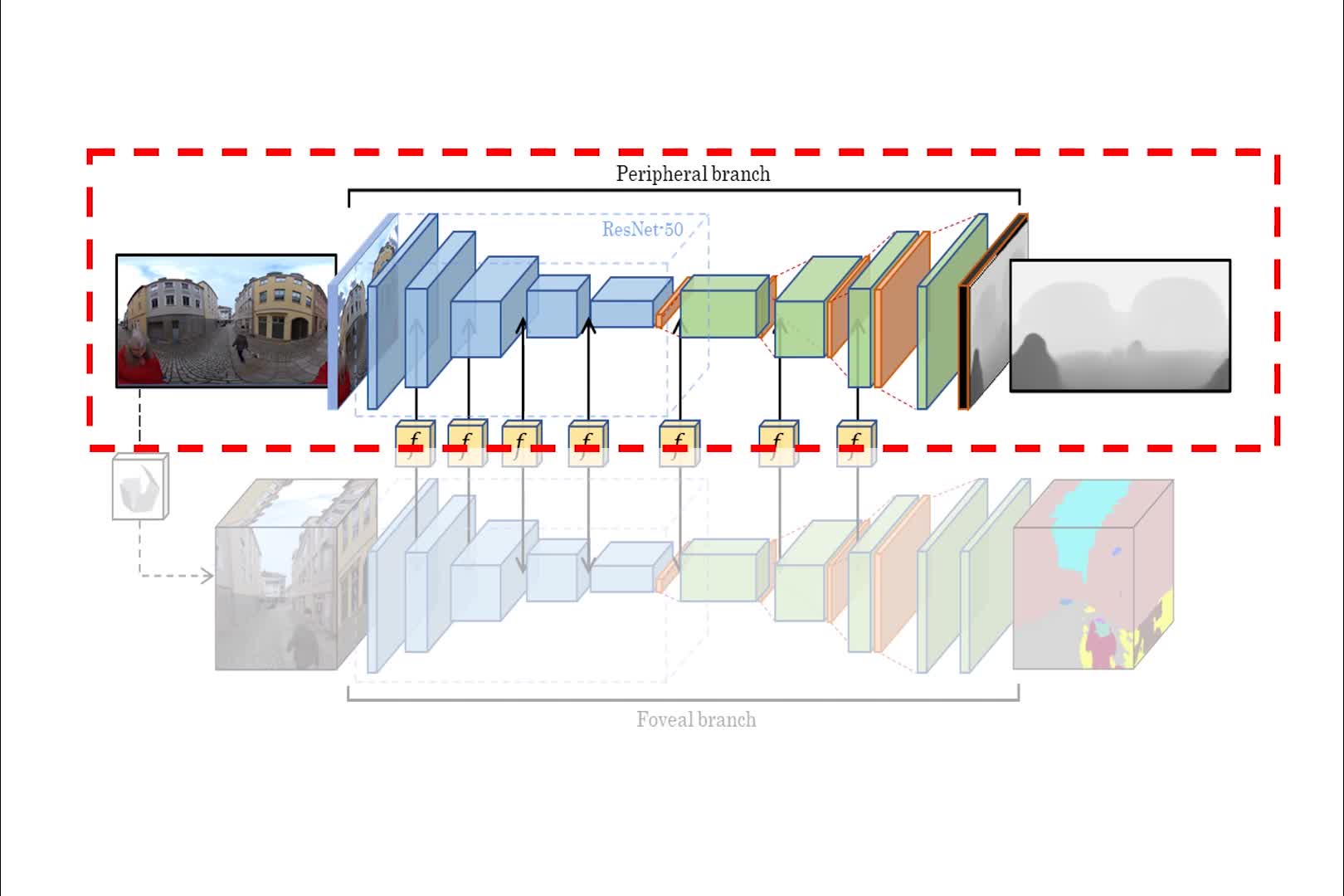
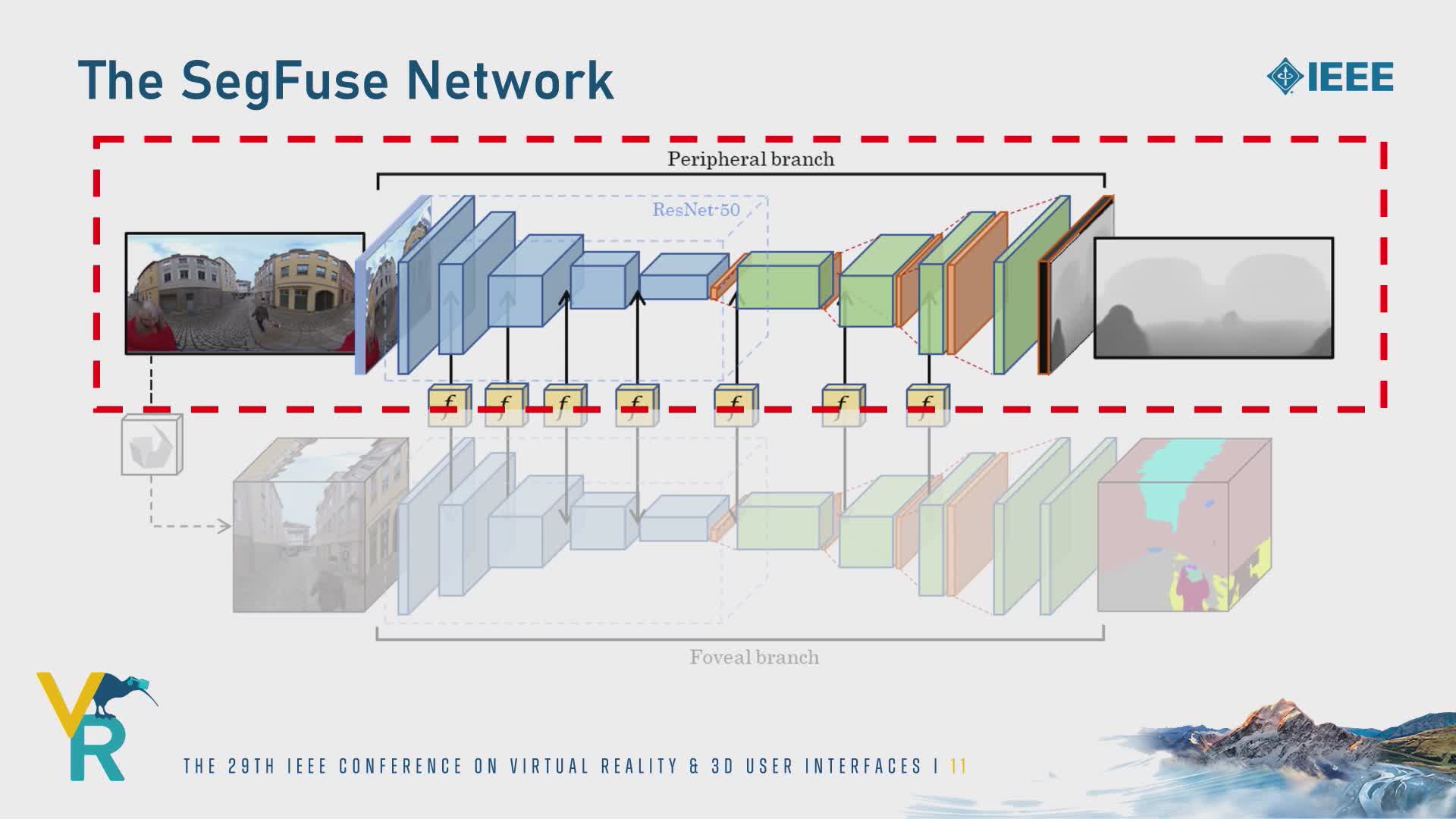
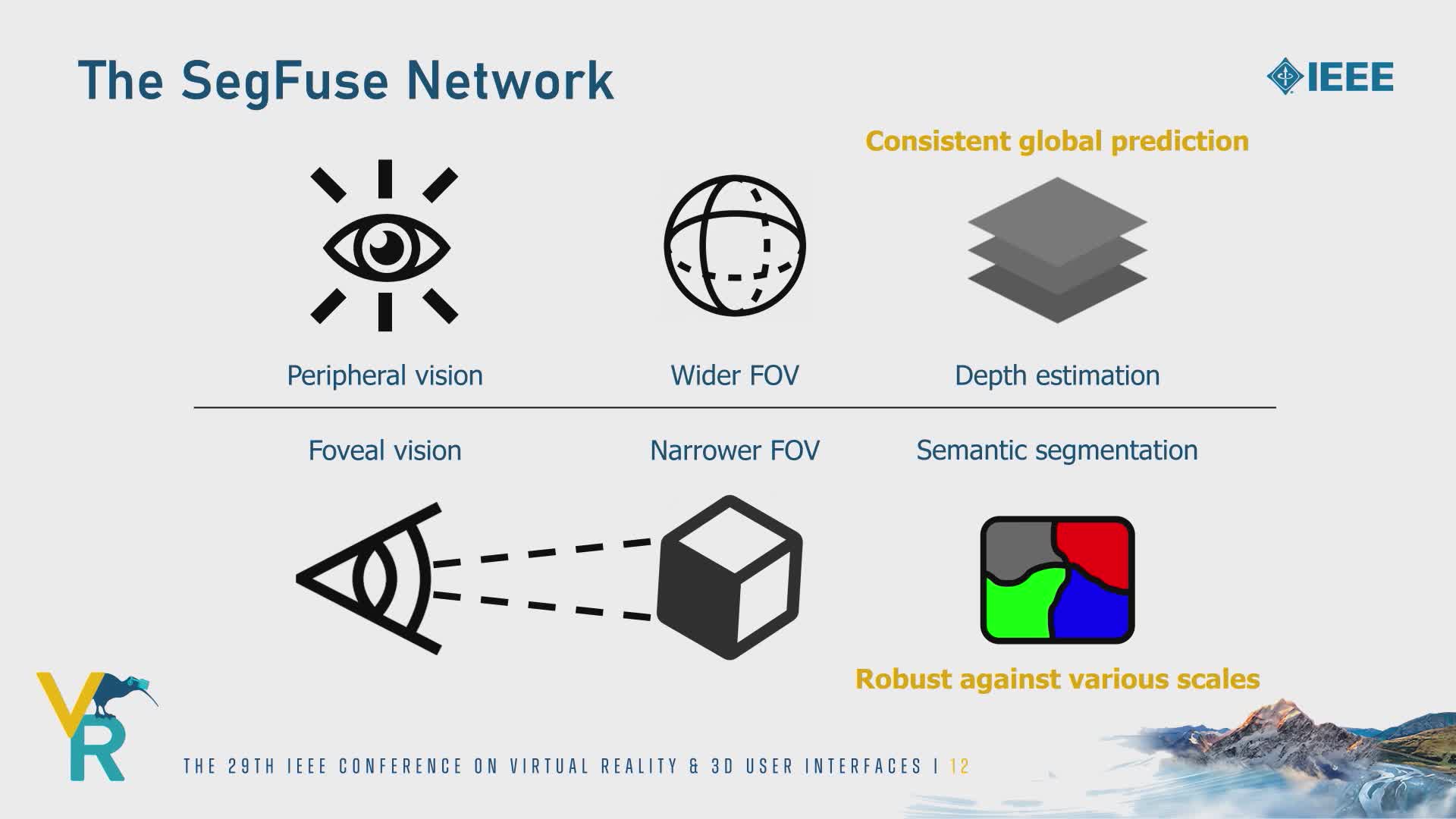
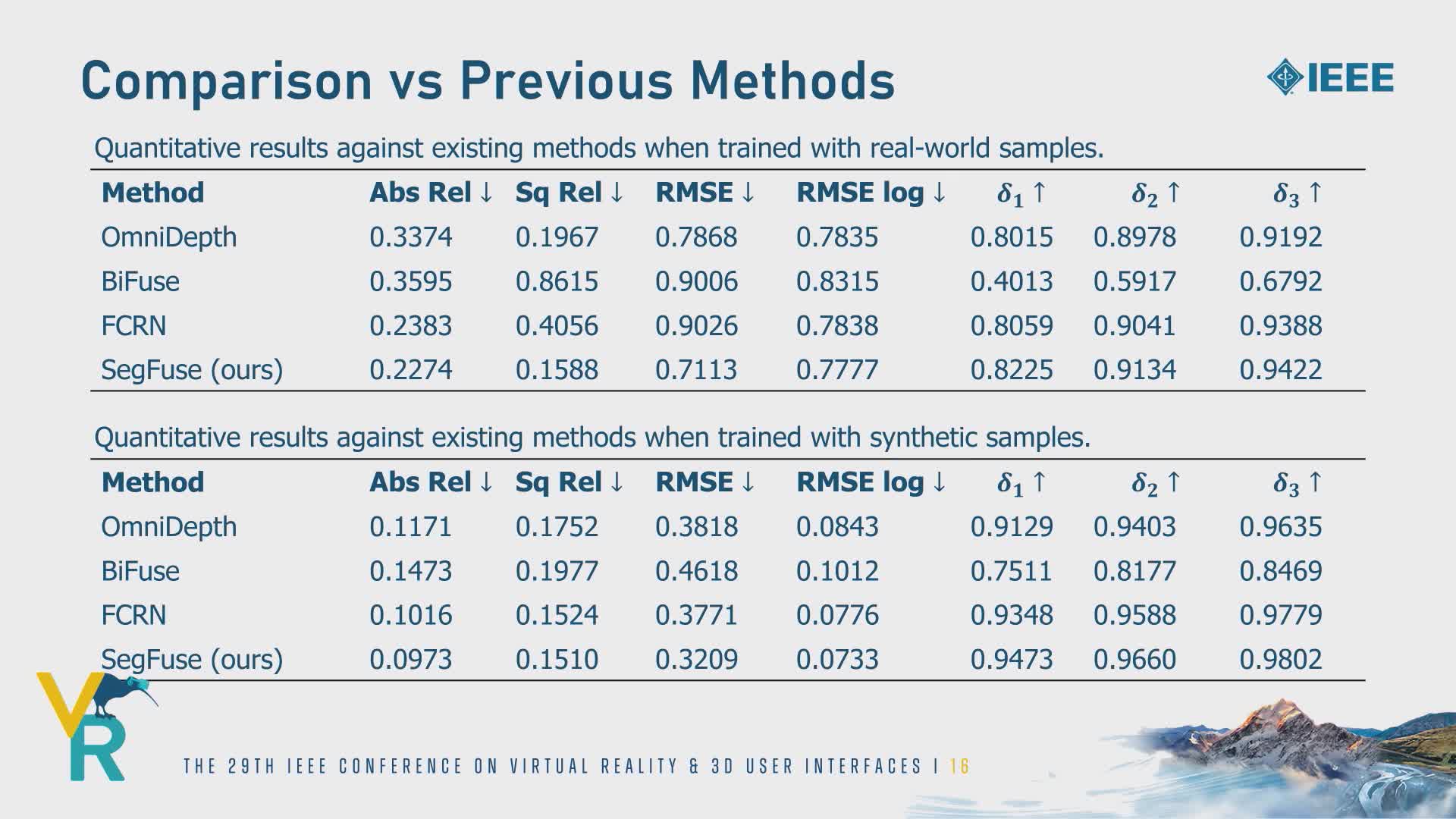
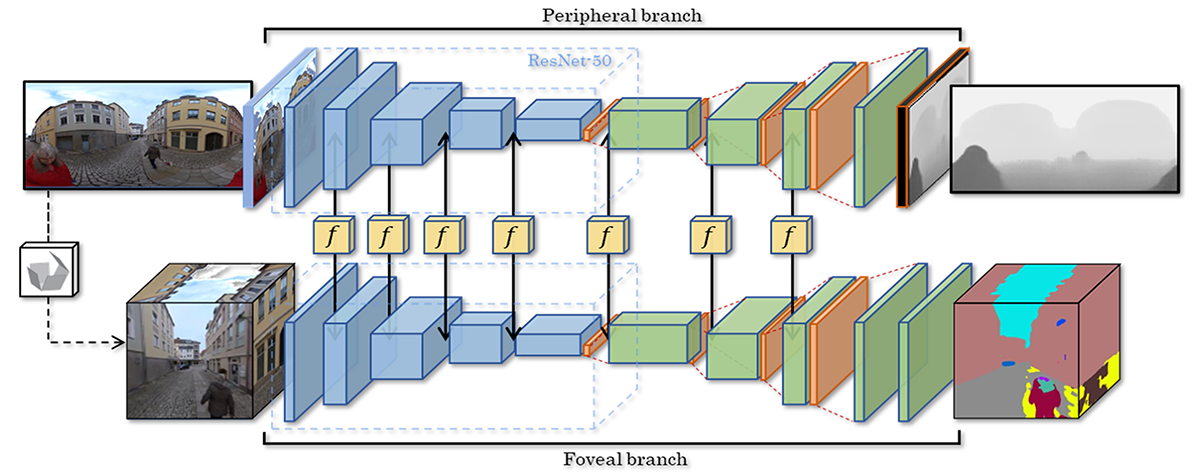
Single-view depth estimation from omnidirectional images has gained popularity with its wide range of applications such as autonomous driving and scene reconstruction. Although data-driven learning-based methods demonstrate significant potential in this field, scarce training data and ineffective 360 estimation algorithms are still two key limitations hindering accurate estimation across diverse domains. In this work, we first establish a large-scale dataset with varied settings called Depth360 to tackle the training data problem. This is achieved by exploring the use of a plenteous source of data, 360 videos from the internet, using a test-time training method that leverages unique information in each omnidirectional sequence. With novel geometric and temporal constraints, our method generates consistent and convincing depth samples to facilitate single-view estimation. We then propose an end-to-end two-branch multi-task learning network, SegFuse, that mimics the human eye to effectively learn from the dataset and estimate high-quality depth maps from diverse monocular RGB images. With a peripheral branch that uses equirectangular projection for depth estimation and a foveal branch that uses cubemap projection for semantic segmentation, our method predicts consistent global depth while maintaining sharp details at local regions. Experimental results show favorable performance against the state-of-the-art methods.