U3DS3: Unsupervised 3D Semantic Scene Segmentation
Jiaxu Liu, Zhengdi Yu, Toby P. Breckon and Hubert P. H. Shum
Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024
H5-Index: 131# Core A Conference‡ Citation: 35#
Abstract
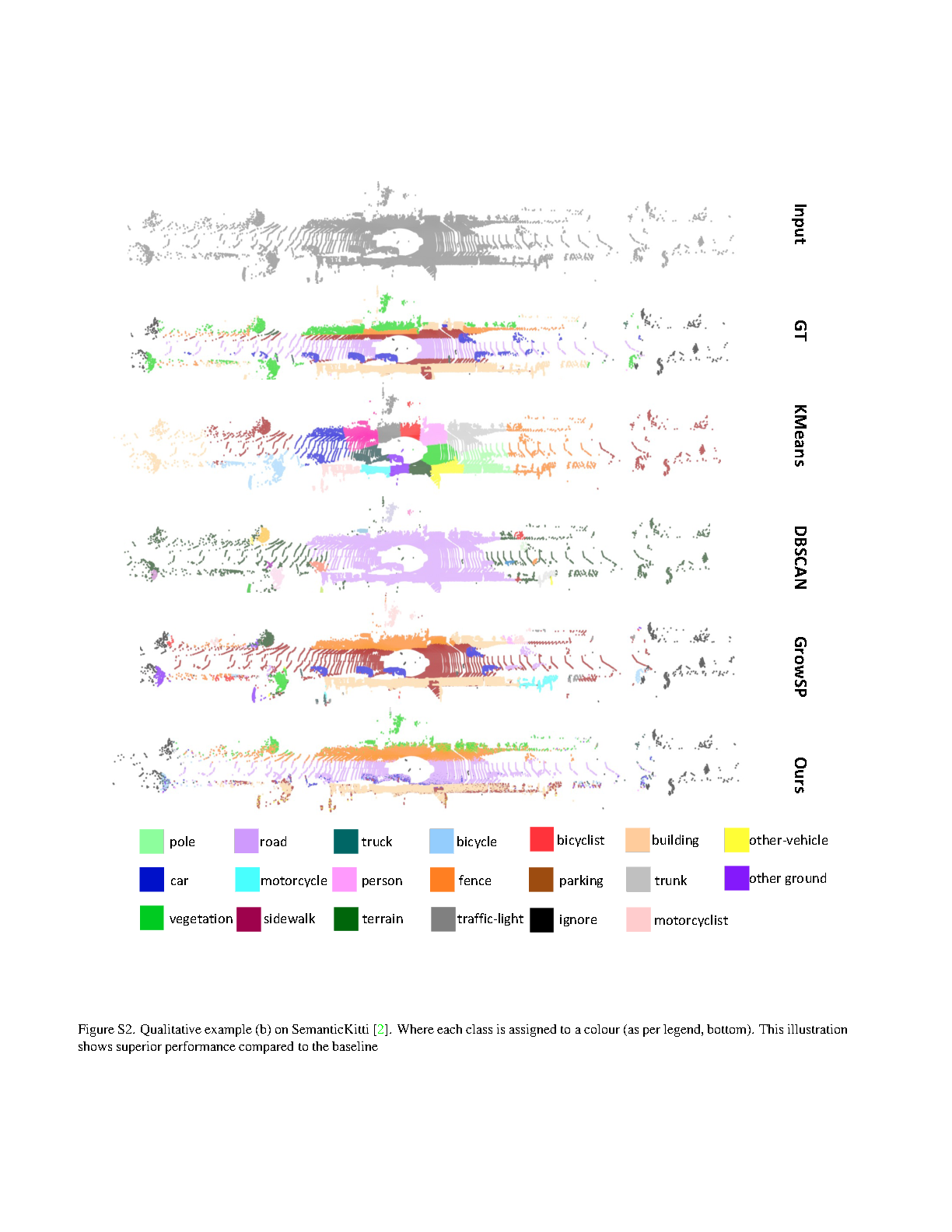
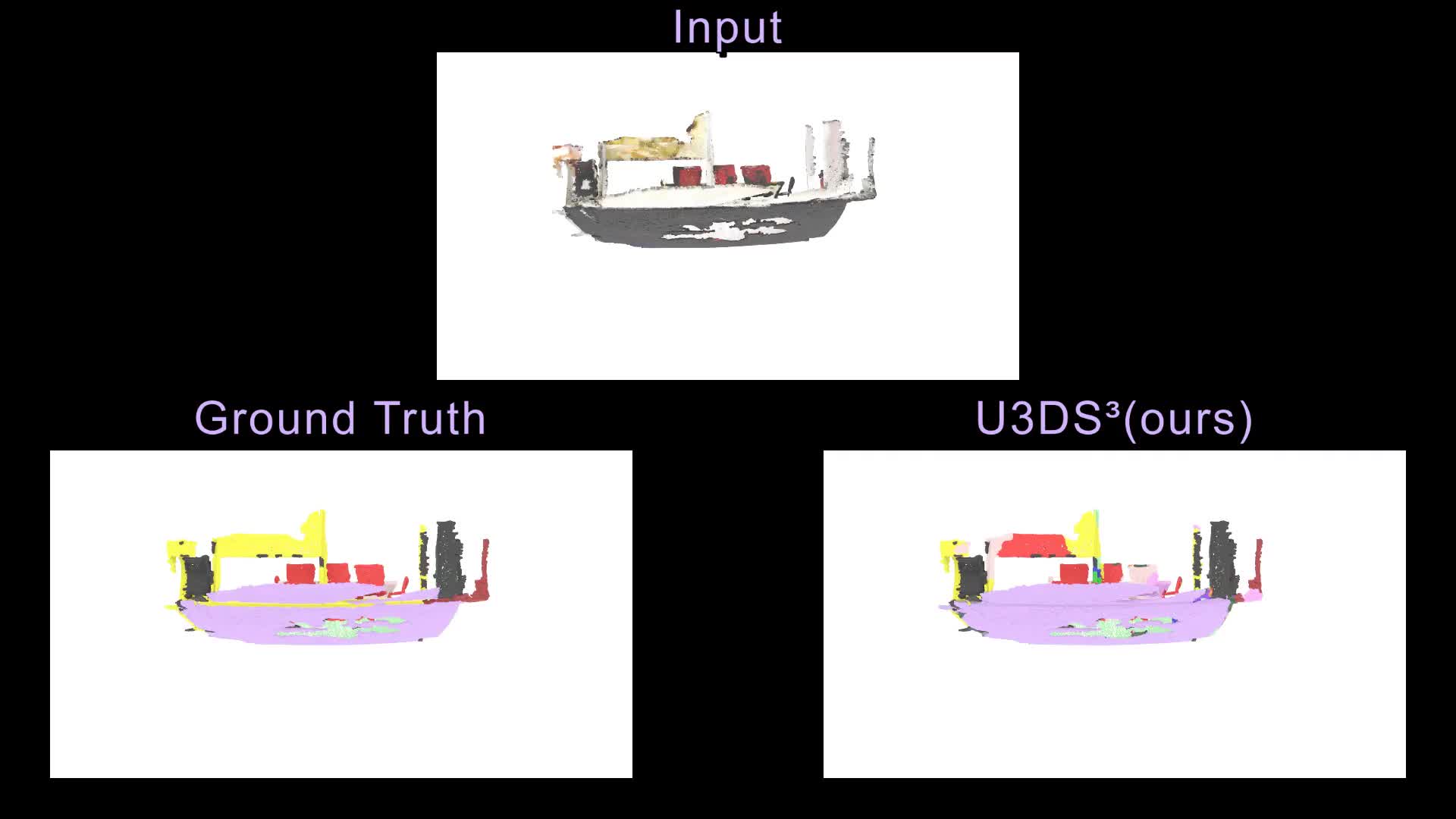
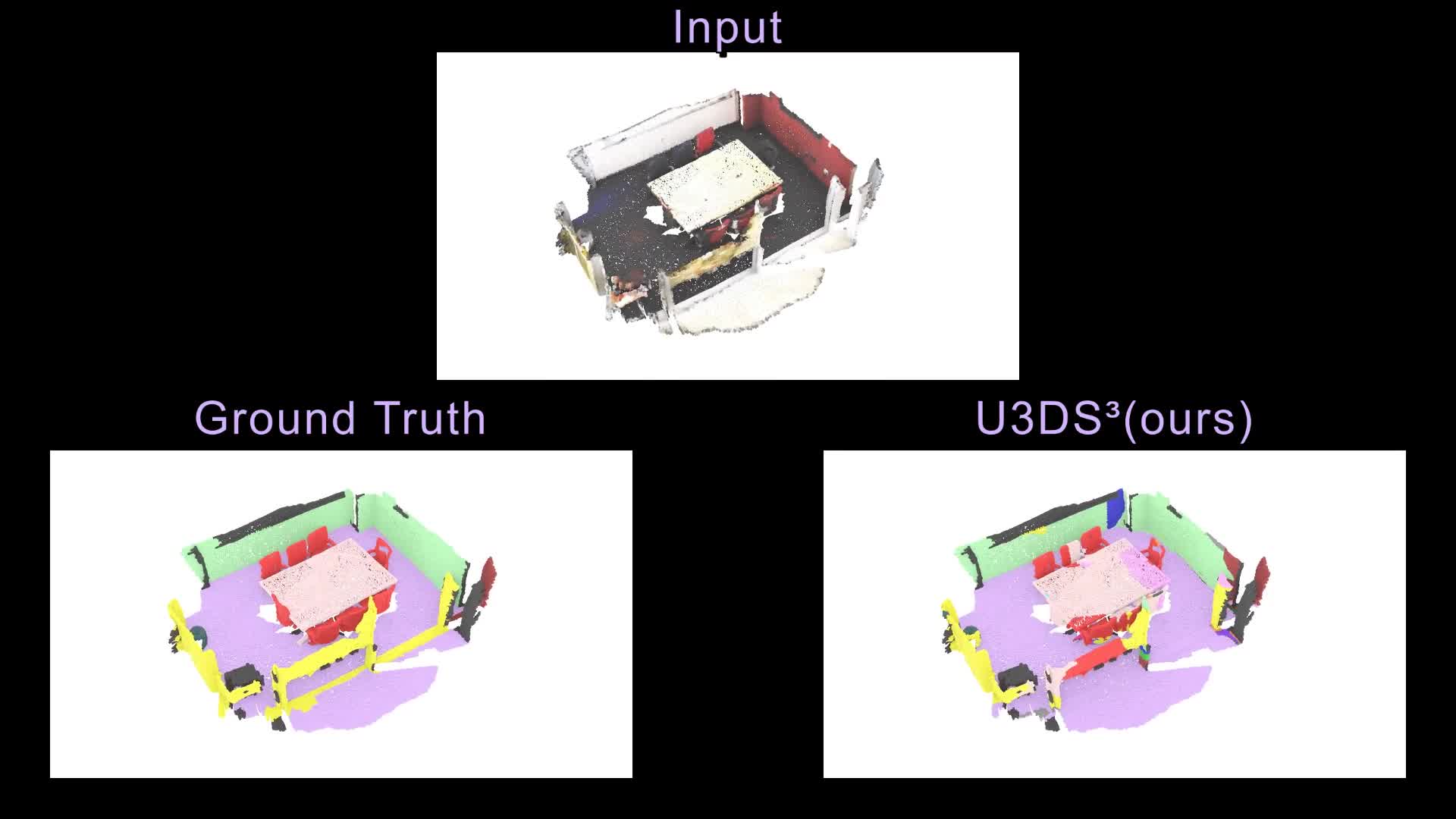
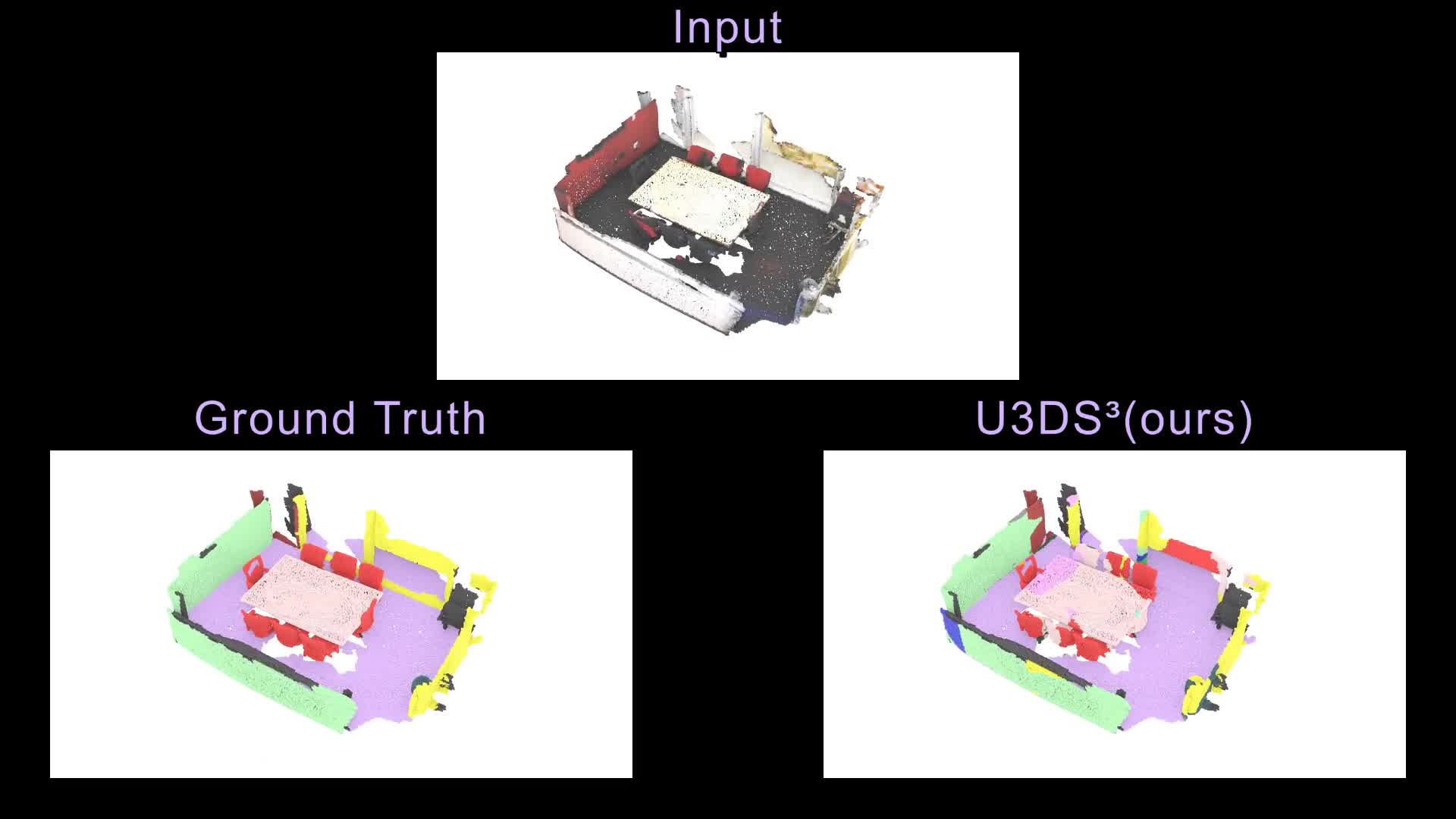
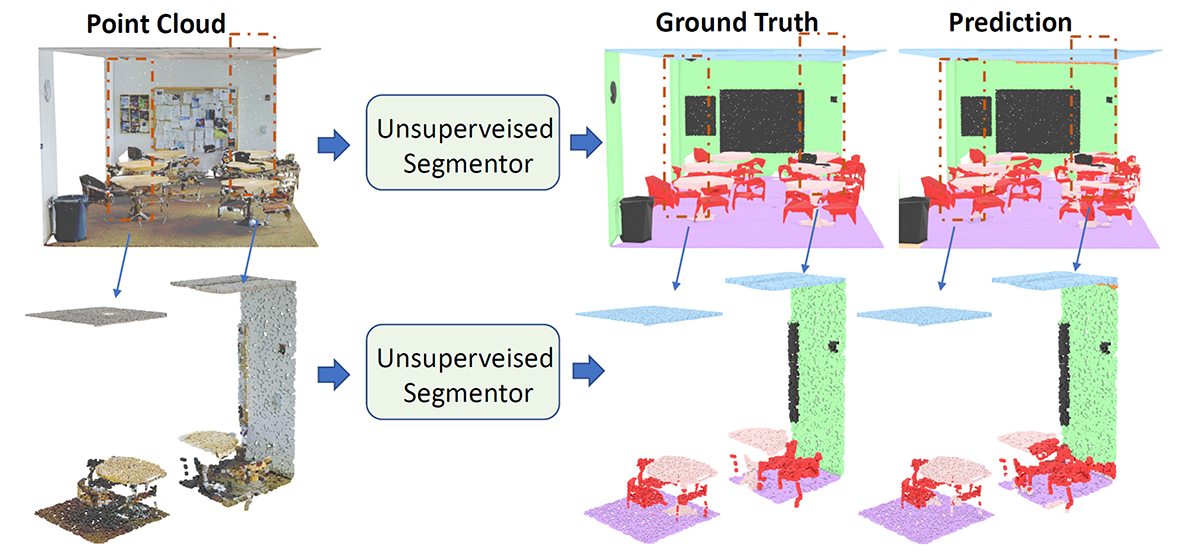
Contemporary point cloud segmentation approaches largely rely on richly annotated 3D training data. However, it is both time-consuming and challenging to obtain consistently accurate annotations for such 3D scene data. Moreover, there is still a lack of investigation into fully unsupervised scene segmentation for point clouds, especially for holistic 3D scenes. This paper presents U3DS³, as a step towards completely unsupervised point cloud segmentation for any holistic 3D scenes. To achieve this, U3DS³ leverages a generalized unsupervised segmentation method for both object and background across both indoor and outdoor static 3D point clouds with no requirement for model pre-training, by leveraging only the inherent information of the point cloud to achieve full 3D scene segmentation. The initial step of our proposed approach involves generating superpoints based on the geometric characteristics of each scene. Subsequently, it undergoes a learning process through a spatial clustering-based methodology, followed by iterative training using pseudo-labels generated in accordance with the cluster centroids. Moreover, by leveraging the invariance and equivariance of the volumetric representations, we apply the geometric transformation on voxelized features to provide two sets of descriptors for robust representation learning. Finally, our evaluation provides state-of-the-art results on the ScanNet and SemanticKitti, and competitive result on the S3DIS benchmark datasets.