Research Publications - Generative AI
Select a Topic:
Go To:
Our Generative AI Research
We design novel generative AI architectures that produces multi-modal outputs, including images, shapes, skeletal motion, and 3D structures, often with controllability features delivered through intuitive user interfaces.
Interested in our research? Consider joining us.


















Journal Papers
Pattern Recognition (PR), 2026
Ziyi Chang, George Alex Koulieris, Hyung Jin Chang and Hubert P. H. Shum
Topics: Literature Review, Generative AI
Webpage Cite This Plain Text
author={Chang, Ziyi and Koulieris, George Alex and Chang, Hyung Jin and Shum, Hubert P. H.},
journal={Pattern Recognition},
title={On the Design Fundamentals of Diffusion Models: A Survey},
year={2026},
pages={111934},
doi={10.1016/j.patcog.2025.111934},
issn={0031-3203},
publisher={Elsevier},
}
AU - Chang, Ziyi
AU - Koulieris, George Alex
AU - Chang, Hyung Jin
AU - Shum, Hubert P. H.
T2 - Pattern Recognition
TI - On the Design Fundamentals of Diffusion Models: A Survey
PY - 2026
SP - 111934
EP - 111934
DO - 10.1016/j.patcog.2025.111934
SN - 0031-3203
PB - Elsevier
ER -
Computer Graphics Forum (CGF) - Proccedings of the 2026 Annual Conference of the European Association for Computer Graphics (Eurographics), 2026
Xiaotang Zhang, Ziyi Chang, Qianhui Men and Hubert P. H. Shum
Topics: Character Animation, Interaction Modelling, Generative AI
Webpage Cite This Plain Text
author={Zhang, Xiaotang and Chang, Ziyi and Men, Qianhui and Shum, Hubert P. H.},
journal={Computer Graphics Forum},
title={Physics-Based Motion Tracking of Contact-Rich Interacting Characters},
year={2026},
pages={e70336},
doi={10.1111/cgf.70336},
publisher={Wiley},
}
AU - Zhang, Xiaotang
AU - Chang, Ziyi
AU - Men, Qianhui
AU - Shum, Hubert P. H.
T2 - Computer Graphics Forum
TI - Physics-Based Motion Tracking of Contact-Rich Interacting Characters
PY - 2026
SP - e70336
EP - e70336
DO - 10.1111/cgf.70336
PB - Wiley
ER -
Computer Graphics Forum (CGF), 2025
Xiaotang Zhang, Ziyi Chang, Qianhui Men and Hubert P. H. Shum
Topics: Character Animation, Interaction Modelling, Generative AI
Webpage Cite This Plain Text
author={Zhang, Xiaotang and Chang, Ziyi and Men, Qianhui and Shum, Hubert P. H.},
journal={Computer Graphics Forum},
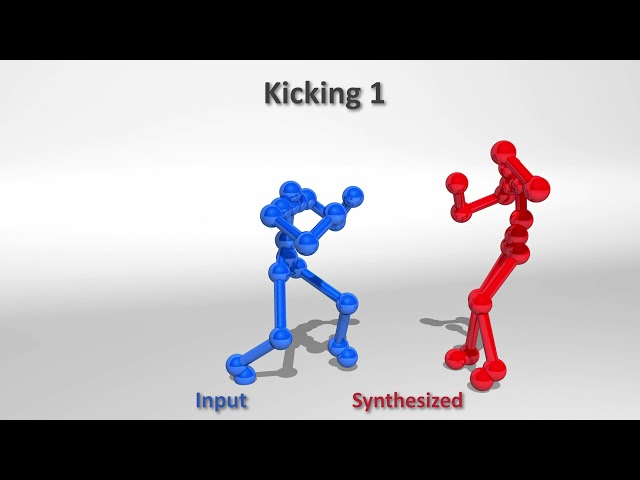
title={Real-time and Controllable Reactive Motion Synthesis via Intention Guidance},
year={2025},
volume={44},
number={6},
pages={e70222},
numpages={11},
doi={10.1111/cgf.70222},
issn={0167-7055},
publisher={Wiley},
}
AU - Zhang, Xiaotang
AU - Chang, Ziyi
AU - Men, Qianhui
AU - Shum, Hubert P. H.
T2 - Computer Graphics Forum
TI - Real-time and Controllable Reactive Motion Synthesis via Intention Guidance
PY - 2025
VL - 44
IS - 6
SP - e70222
EP - e70222
DO - 10.1111/cgf.70222
SN - 0167-7055
PB - Wiley
ER -
IEEE Transactions on Multimedia (TMM), 2024
Shuang Chen, Amir Atapour-Abarghouei and Hubert P. H. Shum
Topics: Generative AI
Webpage Cite This Plain Text
author={Chen, Shuang and Atapour-Abarghouei, Amir and Shum, Hubert P. H.},
journal={IEEE Transactions on Multimedia},
title={HINT: High-quality INpainting Transformer with Mask-Aware Encoding and Enhanced Attention},
year={2024},
volume={26},
pages={7649--7660},
numpages={12},
doi={10.1109/TMM.2024.3369897},
issn={1520-9210 },
publisher={IEEE},
}
AU - Chen, Shuang
AU - Atapour-Abarghouei, Amir
AU - Shum, Hubert P. H.
T2 - IEEE Transactions on Multimedia
TI - HINT: High-quality INpainting Transformer with Mask-Aware Encoding and Enhanced Attention
PY - 2024
VL - 26
SP - 7649
EP - 7660
DO - 10.1109/TMM.2024.3369897
SN - 1520-9210
PB - IEEE
ER -
Software Impacts (SIMPAC), 2023
Shuang Chen, Amir Atapour-Abarghouei, Edmond S. L. Ho and Hubert P. H. Shum
Topics: Biomedical Engineering, Face Modelling, Medical Imaging, Responsible AI, Generative AI
Webpage Cite This Plain Text
author={Chen, Shuang and Atapour-Abarghouei, Amir and Ho, Edmond S. L. and Shum, Hubert P. H.},
journal={Software Impacts},
title={INCLG: Inpainting for Non-Cleft Lip Generation with a Multi-Task Image Processing Network},
year={2023},
volume={17},
pages={100517},
numpages={4},
doi={10.1016/j.simpa.2023.100517},
publisher={Elsevier},
}
AU - Chen, Shuang
AU - Atapour-Abarghouei, Amir
AU - Ho, Edmond S. L.
AU - Shum, Hubert P. H.
T2 - Software Impacts
TI - INCLG: Inpainting for Non-Cleft Lip Generation with a Multi-Task Image Processing Network
PY - 2023
VL - 17
SP - 100517
EP - 100517
DO - 10.1016/j.simpa.2023.100517
PB - Elsevier
ER -
Visual Computer (VC), 2022
Naoki Nozawa, Hubert P. H. Shum, Qi Feng, Edmond S. L. Ho and Shigeo Morishima
Topics: 3D Reconstruction, Surface Modelling, Artwork Analysis, Generative AI
Webpage Cite This Plain Text
author={Nozawa, Naoki and Shum, Hubert P. H. and Feng, Qi and Ho, Edmond S. L. and Morishima, Shigeo},
journal={Visual Computer},
title={3D Car Shape Reconstruction from a Contour Sketch using GAN and Lazy Learning},
year={2022},
volume={38},
number={4},
pages={1317--1330},
numpages={14},
doi={10.1007/s00371-020-02024-y},
issn={1432-2315},
publisher={Springer},
}
AU - Nozawa, Naoki
AU - Shum, Hubert P. H.
AU - Feng, Qi
AU - Ho, Edmond S. L.
AU - Morishima, Shigeo
T2 - Visual Computer
TI - 3D Car Shape Reconstruction from a Contour Sketch using GAN and Lazy Learning
PY - 2022
VL - 38
IS - 4
SP - 1317
EP - 1330
DO - 10.1007/s00371-020-02024-y
SN - 1432-2315
PB - Springer
ER -
Computers and Graphics (C&G), 2022
Qianhui Men, Hubert P. H. Shum, Edmond S. L. Ho and Howard Leung
Topics: Character Animation, Interaction Modelling, Generative AI
Webpage Cite This Plain Text
author={Men, Qianhui and Shum, Hubert P. H. and Ho, Edmond S. L. and Leung, Howard},
journal={Computers and Graphics},
title={GAN-Based Reactive Motion Synthesis with Class-Aware Discriminators for Human-Human Interaction},
year={2022},
volume={102},
pages={634--645},
numpages={12},
doi={10.1016/j.cag.2021.09.014},
issn={0097-8493},
publisher={Elsevier},
}
AU - Men, Qianhui
AU - Shum, Hubert P. H.
AU - Ho, Edmond S. L.
AU - Leung, Howard
T2 - Computers and Graphics
TI - GAN-Based Reactive Motion Synthesis with Class-Aware Discriminators for Human-Human Interaction
PY - 2022
VL - 102
SP - 634
EP - 645
DO - 10.1016/j.cag.2021.09.014
SN - 0097-8493
PB - Elsevier
ER -
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2021
He Wang, Edmond S. L. Ho, Hubert P. H. Shum and Zhanxing Zhu
Topics: Character Animation, Generative AI
Webpage Cite This Plain Text
author={Wang, He and Ho, Edmond S. L. and Shum, Hubert P. H. and Zhu, Zhanxing},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={Spatio-Temporal Manifold Learning for Human Motions via Long-Horizon Modeling},
year={2021},
volume={27},
number={1},
pages={216--227},
numpages={12},
doi={10.1109/TVCG.2019.2936810},
publisher={IEEE},
}
AU - Wang, He
AU - Ho, Edmond S. L.
AU - Shum, Hubert P. H.
AU - Zhu, Zhanxing
T2 - IEEE Transactions on Visualization and Computer Graphics
TI - Spatio-Temporal Manifold Learning for Human Motions via Long-Horizon Modeling
PY - 2021
VL - 27
IS - 1
SP - 216
EP - 227
DO - 10.1109/TVCG.2019.2936810
PB - IEEE
ER -
Conference Papers
Proceedings of the 2026 International Conference on Pattern Recognition (ICPR), 2026
Jamie Stirling, Noura Al Moubayed and Hubert P. H. Shum
Topics: Generative AI
Webpage Cite This Plain Text
author={Stirling, Jamie and Moubayed, Noura Al and Shum, Hubert P. H.},
booktitle={Proceedings of the 2026 International Conference on Pattern Recognition},
title={Investigating Permutation-Invariant Discrete Representation Learning for Spatially Aligned Images},
year={2026},
location={Lyon, France},
}
AU - Stirling, Jamie
AU - Moubayed, Noura Al
AU - Shum, Hubert P. H.
T2 - Proceedings of the 2026 International Conference on Pattern Recognition
TI - Investigating Permutation-Invariant Discrete Representation Learning for Spatially Aligned Images
PY - 2026
ER -
Proceedings of the 2026 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop (CVPRW), 2026
Jiaxu Liu, Li Li, Hubert P. H. Shum and Toby P. Breckon
Topics: Generative AI
Webpage Cite This Plain Text
author={Liu, Jiaxu and Li, Li and Shum, Hubert P. H. and Breckon, Toby P.},
booktitle={Proceedings of the 2026 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop},
title={TFDM: Time-Variant Frequency-Based Point Cloud Diffusion with State Space Model},
year={2026},
pages={4667--4676},
numpages={10},
publisher={IEEE/CVF},
location={Colorado, USA},
}
AU - Liu, Jiaxu
AU - Li, Li
AU - Shum, Hubert P. H.
AU - Breckon, Toby P.
T2 - Proceedings of the 2026 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop
TI - TFDM: Time-Variant Frequency-Based Point Cloud Diffusion with State Space Model
PY - 2026
SP - 4667
EP - 4676
PB - IEEE/CVF
ER -
Proceedings of the 2026 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop (CVPRW), 2026
Jamie Stirling, Noura Al Moubayed, Chris G. Willcocks and Hubert P. H. Shum
Topics: Generative AI
Webpage Cite This Plain Text
author={Stirling, Jamie and Moubayed, Noura Al and Willcocks, Chris G. and Shum, Hubert P. H.},
booktitle={Proceedings of the 2026 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop},
title={Controllable Image Generation with Composed Parallel Token Prediction},
year={2026},
pages={5074--5083},
publisher={IEEE/CVF},
location={Colorado, USA},
}
AU - Stirling, Jamie
AU - Moubayed, Noura Al
AU - Willcocks, Chris G.
AU - Shum, Hubert P. H.
T2 - Proceedings of the 2026 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop
TI - Controllable Image Generation with Composed Parallel Token Prediction
PY - 2026
SP - 5074
EP - 5083
PB - IEEE/CVF
ER -
Proceedings of the 2025 ACM SIGGRAPH, 2025
Ziyi Chang, He Wang, George Alex Koulieris and Hubert P. H. Shum
Topics: Character Animation, Interaction Modelling, Crowd Modelling, Generative AI
Webpage Cite This Plain Text
author={Chang, Ziyi and Wang, He and Koulieris, George Alex and Shum, Hubert P. H.},
booktitle={Proceedings of the 2025 ACM SIGGRAPH},
title={Large-Scale Multi-Character Interaction Synthesis},
year={2025},
pages={Article 114},
numpages={10},
doi={10.1145/3721238.3730750},
isbn={9.80E+12},
publisher={ACM},
Address={New York, NY, USA},
location={Vancouver, Canada},
}
AU - Chang, Ziyi
AU - Wang, He
AU - Koulieris, George Alex
AU - Shum, Hubert P. H.
T2 - Proceedings of the 2025 ACM SIGGRAPH
TI - Large-Scale Multi-Character Interaction Synthesis
PY - 2025
SP - Article 114
EP - Article 114
DO - 10.1145/3721238.3730750
SN - 9.80E+12
PB - ACM
ER -
Proceedings of the 2025 ACM SIGGRAPH Asia, 2025
Xiaotang Zhang, Ziyi Chang, Qianhui Men and Hubert P. H. Shum
Topics: Character Animation, Interaction Modelling, Generative AI
Webpage Cite This Plain Text
author={Zhang, Xiaotang and Chang, Ziyi and Men, Qianhui and Shum, Hubert P. H.},
booktitle={Proceedings of the 2025 ACM SIGGRAPH Asia},
title={Motion In-Betweening for Densely Interacting Characters},
year={2025},
pages={96},
numpages={11},
doi={10.1145/3757377.3763950},
isbn={9.80E+12},
publisher={ACM},
Address={New York, NY, USA},
location={Hong Kong, China},
}
AU - Zhang, Xiaotang
AU - Chang, Ziyi
AU - Men, Qianhui
AU - Shum, Hubert P. H.
T2 - Proceedings of the 2025 ACM SIGGRAPH Asia
TI - Motion In-Betweening for Densely Interacting Characters
PY - 2025
SP - 96
EP - 96
DO - 10.1145/3757377.3763950
SN - 9.80E+12
PB - ACM
ER -
Proceedings of the 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025
Shuang Chen, Haozheng Zhang, Amir Atapour-Abarghouei and Hubert P. H. Shum
Topics: Generative AI
Webpage Cite This Plain Text
author={Chen, Shuang and Zhang, Haozheng and Atapour-Abarghouei, Amir and Shum, Hubert P. H.},
booktitle={Proceedings of the 2025 IEEE/CVF Winter Conference on Applications of Computer Vision},
series={WACV '25},
title={SEM-Net: Efficient Pixel Modelling for Image Inpainting with Spatially Enhanced SSM},
year={2025},
pages={461--471},
doi={10.1109/WACV61041.2025.00055},
publisher={IEEE/CVF},
location={Arizona, USA},
}
AU - Chen, Shuang
AU - Zhang, Haozheng
AU - Atapour-Abarghouei, Amir
AU - Shum, Hubert P. H.
T2 - Proceedings of the 2025 IEEE/CVF Winter Conference on Applications of Computer Vision
TI - SEM-Net: Efficient Pixel Modelling for Image Inpainting with Spatially Enhanced SSM
PY - 2025
SP - 461
EP - 471
DO - 10.1109/WACV61041.2025.00055
PB - IEEE/CVF
ER -
Proceedings of the 2024 British Machine Vision Conference (BMVC), 2024
Shuang Chen, Amir Atapour-Abarghouei, Haozheng Zhang and Hubert P. H. Shum
Topics: Generative AI
Webpage Cite This Plain Text
author={Chen, Shuang and Atapour-Abarghouei, Amir and Zhang, Haozheng and Shum, Hubert P. H.},
booktitle={Proceedings of the 2024 British Machine Vision Conference},
series={BMVC '24},
title={MxT: Mamba x Transformer for Image Inpainting},
year={2024},
location={Glasgow, UK},
}
AU - Chen, Shuang
AU - Atapour-Abarghouei, Amir
AU - Zhang, Haozheng
AU - Shum, Hubert P. H.
T2 - Proceedings of the 2024 British Machine Vision Conference
TI - MxT: Mamba x Transformer for Image Inpainting
PY - 2024
ER -
Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2024
Abril Corona-Figueroa, Hubert P. H. Shum and Chris G. Willcocks
Topics: 3D Reconstruction, Biomedical Engineering, Medical Imaging, Generative AI
Webpage Cite This Plain Text
author={Corona-Figueroa, Abril and Shum, Hubert P. H. and Willcocks, Chris G.},
booktitle={Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops},
series={CVPRW '24},
title={Repeat and Concatenate: 2D to 3D Image Translation with 3D to 3D Generative Modeling},
year={2024},
pages={2315--2324},
numpages={10},
doi={10.1109/CVPRW63382.2024.00237},
publisher={IEEE/CVF},
location={Seattle, USA},
}
AU - Corona-Figueroa, Abril
AU - Shum, Hubert P. H.
AU - Willcocks, Chris G.
T2 - Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops
TI - Repeat and Concatenate: 2D to 3D Image Translation with 3D to 3D Generative Modeling
PY - 2024
SP - 2315
EP - 2324
DO - 10.1109/CVPRW63382.2024.00237
PB - IEEE/CVF
ER -
Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023
Abril Corona-Figueroa, Sam Bond-Taylor, Neelanjan Bhowmik, Yona Falinie A. Gaus, Toby P. Breckon, Hubert P. H. Shum and Chris G. Willcocks
Topics: 3D Reconstruction, Generative AI
Webpage Cite This Plain Text
author={Corona-Figueroa, Abril and Bond-Taylor, Sam and Bhowmik, Neelanjan and Gaus, Yona Falinie A. and Breckon, Toby P. and Shum, Hubert P. H. and Willcocks, Chris G.},
booktitle={Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision},
series={ICCV '23},
title={Unaligned 2D to 3D Translation with Conditional Vector-Quantized Code Diffusion using Transformers},
year={2023},
month={10},
pages={14539--14548},
numpages={10},
doi={10.1109/ICCV51070.2023.01341},
publisher={IEEE/CVF},
location={Paris, France},
}
AU - Corona-Figueroa, Abril
AU - Bond-Taylor, Sam
AU - Bhowmik, Neelanjan
AU - Gaus, Yona Falinie A.
AU - Breckon, Toby P.
AU - Shum, Hubert P. H.
AU - Willcocks, Chris G.
T2 - Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision
TI - Unaligned 2D to 3D Translation with Conditional Vector-Quantized Code Diffusion using Transformers
PY - 2023
Y1 - 10 2023
SP - 14539
EP - 14548
DO - 10.1109/ICCV51070.2023.01341
PB - IEEE/CVF
ER -
Proceedings of the 2023 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), 2023
Qi Feng, Hubert P. H. Shum and Shigeo Morishima
Topics: Virtual Reality, Environment Sensing, Video Analysis, Generative AI
Webpage Cite This Plain Text
author={Feng, Qi and Shum, Hubert P. H. and Morishima, Shigeo},
booktitle={Proceedings of the 2023 IEEE International Symposium on Mixed and Augmented Reality},
series={ISMAR '23},
title={Enhancing Perception and Immersion in Pre-Captured Environments through Learning-Based Eye Height Adaptation},
year={2023},
month={10},
pages={405-414},
numpages={10},
doi={10.1109/ISMAR59233.2023.00055},
publisher={IEEE},
location={Sydney, Australia},
}
AU - Feng, Qi
AU - Shum, Hubert P. H.
AU - Morishima, Shigeo
T2 - Proceedings of the 2023 IEEE International Symposium on Mixed and Augmented Reality
TI - Enhancing Perception and Immersion in Pre-Captured Environments through Learning-Based Eye Height Adaptation
PY - 2023
Y1 - 10 2023
SP - 405-414
EP - 405-414
DO - 10.1109/ISMAR59233.2023.00055
PB - IEEE
ER -
Proceedings of the 2023 International Conference on Computer Graphics Theory and Applications (GRAPP), 2023
Ziyi Chang, Edmund J. C. Findlay, Haozheng Zhang and Hubert P. H. Shum
Topics: Character Animation, Generative AI
Webpage Cite This Plain Text
author={Chang, Ziyi and Findlay, Edmund J. C. and Zhang, Haozheng and Shum, Hubert P. H.},
booktitle={Proceedings of the 2023 International Conference on Computer Graphics Theory and Applications},
series={GRAPP '23},
title={Unifying Human Motion Synthesis and Style Transfer with Denoising Diffusion Probabilistic Models},
year={2023},
month={2},
pages={64--74},
numpages={11},
doi={10.5220/0011631000003417},
issn={2184-4321},
isbn={978-989-758-634-7},
publisher={SciTePress},
location={Lisbon, Portugal},
}
AU - Chang, Ziyi
AU - Findlay, Edmund J. C.
AU - Zhang, Haozheng
AU - Shum, Hubert P. H.
T2 - Proceedings of the 2023 International Conference on Computer Graphics Theory and Applications
TI - Unifying Human Motion Synthesis and Style Transfer with Denoising Diffusion Probabilistic Models
PY - 2023
Y1 - 2 2023
SP - 64
EP - 74
DO - 10.5220/0011631000003417
SN - 2184-4321
PB - SciTePress
ER -
Proceedings of the 2022 ACM Symposium on Virtual Reality Software and Technology (VRST), 2022
Ziyi Chang, George Alex Koulieris and Hubert P. H. Shum
Topics: 3D Reconstruction, Surface Modelling, Artwork Analysis, Generative AI
Webpage Cite This Plain Text
author={Chang, Ziyi and Koulieris, George Alex and Shum, Hubert P. H.},
booktitle={Proceedings of the 2022 ACM Symposium on Virtual Reality Software and Technology},
series={VRST '22},
title={3D Reconstruction of Sculptures from Single Images via Unsupervised Domain Adaptation on Implicit Models},
year={2022},
month={11},
pages={1--10},
numpages={10},
doi={10.1145/3562939.3565632},
isbn={9.78E+12},
publisher={ACM},
Address={New York, NY, USA},
location={Tsukuba, Japan},
}
AU - Chang, Ziyi
AU - Koulieris, George Alex
AU - Shum, Hubert P. H.
T2 - Proceedings of the 2022 ACM Symposium on Virtual Reality Software and Technology
TI - 3D Reconstruction of Sculptures from Single Images via Unsupervised Domain Adaptation on Implicit Models
PY - 2022
Y1 - 11 2022
SP - 1
EP - 10
DO - 10.1145/3562939.3565632
SN - 9.78E+12
PB - ACM
ER -
Proceedings of the 2022 International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), 2022
Abril Corona-Figueroa, Jonathan Frawley, Sam Bond-Taylor, Sarath Bethapudi, Hubert P. H. Shum and Chris G. Willcocks
Topics: Biomedical Engineering, 3D Reconstruction, Medical Imaging, Generative AI
Webpage Cite This Plain Text
author={Corona-Figueroa, Abril and Frawley, Jonathan and Bond-Taylor, Sam and Bethapudi, Sarath and Shum, Hubert P. H. and Willcocks, Chris G.},
booktitle={Proceedings of the 2022 International Conference of the IEEE Engineering in Medicine and Biology Society},
series={EMBC '22},
title={MedNeRF: Medical Neural Radiance Fields for Reconstructing 3D-Aware CT-projections from a Single X-ray},
year={2022},
month={7},
pages={3843--3848},
numpages={6},
doi={10.1109/EMBC48229.2022.9871757},
publisher={IEEE},
location={Glasgow, UK},
}
AU - Corona-Figueroa, Abril
AU - Frawley, Jonathan
AU - Bond-Taylor, Sam
AU - Bethapudi, Sarath
AU - Shum, Hubert P. H.
AU - Willcocks, Chris G.
T2 - Proceedings of the 2022 International Conference of the IEEE Engineering in Medicine and Biology Society
TI - MedNeRF: Medical Neural Radiance Fields for Reconstructing 3D-Aware CT-projections from a Single X-ray
PY - 2022
Y1 - 7 2022
SP - 3843
EP - 3848
DO - 10.1109/EMBC48229.2022.9871757
PB - IEEE
ER -
Proceedings of the 2022 IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI), 2022
Shuang Chen, Amir Atapour-Abarghouei, Jane Kerby, Edmond S. L. Ho, David C. G. Sainsbury, Sophie Butterworth and Hubert P. H. Shum
Topics: Biomedical Engineering, Face Modelling, Medical Imaging, Responsible AI, Generative AI
Webpage Cite This Plain Text
author={Chen, Shuang and Atapour-Abarghouei, Amir and Kerby, Jane and Ho, Edmond S. L. and Sainsbury, David C. G. and Butterworth, Sophie and Shum, Hubert P. H.},
booktitle={Proceedings of the 2022 IEEE-EMBS International Conference on Biomedical and Health Informatics},
series={BHI '22},
title={A Feasibility Study on Image Inpainting for Non-Cleft Lip Generation from Patients with Cleft Lip},
year={2022},
month={9},
pages={1--4},
numpages={4},
doi={10.1109/BHI56158.2022.9926917},
publisher={IEEE},
location={Ioannina, Greece},
}
AU - Chen, Shuang
AU - Atapour-Abarghouei, Amir
AU - Kerby, Jane
AU - Ho, Edmond S. L.
AU - Sainsbury, David C. G.
AU - Butterworth, Sophie
AU - Shum, Hubert P. H.
T2 - Proceedings of the 2022 IEEE-EMBS International Conference on Biomedical and Health Informatics
TI - A Feasibility Study on Image Inpainting for Non-Cleft Lip Generation from Patients with Cleft Lip
PY - 2022
Y1 - 9 2022
SP - 1
EP - 4
DO - 10.1109/BHI56158.2022.9926917
PB - IEEE
ER -
Proceedings of the 2020 International Conference on Pattern Recognition (ICPR), 2020
Daniel Organisciak, Edmond S. L. Ho and Hubert P. H. Shum
Topics: Face Modelling, Generative AI
Webpage Cite This Plain Text
author={Organisciak, Daniel and Ho, Edmond S. L. and Shum, Hubert P. H.},
booktitle={Proceedings of the 2020 International Conference on Pattern Recognition},
series={ICPR '20},
title={Makeup Style Transfer on Low-Quality Images with Weighted Multi-Scale Attention},
year={2020},
month={1},
pages={6011--6018},
numpages={8},
doi={10.1109/ICPR48806.2021.9412604},
location={Milan, Italy},
}
AU - Organisciak, Daniel
AU - Ho, Edmond S. L.
AU - Shum, Hubert P. H.
T2 - Proceedings of the 2020 International Conference on Pattern Recognition
TI - Makeup Style Transfer on Low-Quality Images with Weighted Multi-Scale Attention
PY - 2020
Y1 - 1 2020
SP - 6011
EP - 6018
DO - 10.1109/ICPR48806.2021.9412604
ER -
Proceedings of the 2020 International Conference on Computer Graphics Theory and Applications (GRAPP), 2020
Naoki Nozawa, Hubert P. H. Shum, Edmond S. L. Ho and Shigeo Morishima
Topics: 3D Reconstruction, Surface Modelling, Artwork Analysis, Generative AI
Webpage Cite This Plain Text
author={Nozawa, Naoki and Shum, Hubert P. H. and Ho, Edmond S. L. and Morishima, Shigeo},
booktitle={Proceedings of the 2020 International Conference on Computer Graphics Theory and Applications},
series={GRAPP '20},
title={Single Sketch Image Based 3D Car Shape Reconstruction with Deep Learning and Lazy Learning},
year={2020},
month={2},
pages={179--190},
numpages={12},
doi={10.5220/0009157001790190},
issn={2184-4321},
isbn={978-989-758-402-2},
publisher={SciTePress},
location={Valletta, Malta},
}
AU - Nozawa, Naoki
AU - Shum, Hubert P. H.
AU - Ho, Edmond S. L.
AU - Morishima, Shigeo
T2 - Proceedings of the 2020 International Conference on Computer Graphics Theory and Applications
TI - Single Sketch Image Based 3D Car Shape Reconstruction with Deep Learning and Lazy Learning
PY - 2020
Y1 - 2 2020
SP - 179
EP - 190
DO - 10.5220/0009157001790190
SN - 2184-4321
PB - SciTePress
ER -
Proceedings of the 2019 ACM SIGGRAPH Conference on Motion, Interaction and Games (MIG), 2019
Shanfeng Hu, Hubert P. H. Shum and Antonio Mucherino
Topics: Surface Modelling, Generative AI
Webpage Cite This Plain Text
author={Hu, Shanfeng and Shum, Hubert P. H. and Mucherino, Antonio},
booktitle={Proceedings of the 2019 ACM SIGGRAPH Conference on Motion, Interaction and Games},
series={MIG '19},
title={DSPP: Deep Shape and Pose Priors of Humans},
year={2019},
month={10},
pages={1:1--1:6},
numpages={6},
doi={10.1145/3359566.3360051},
isbn={978-1-4503-6994-7},
publisher={ACM},
Address={New York, NY, USA},
location={Newcastle upon Tyne, UK},
}
AU - Hu, Shanfeng
AU - Shum, Hubert P. H.
AU - Mucherino, Antonio
T2 - Proceedings of the 2019 ACM SIGGRAPH Conference on Motion, Interaction and Games
TI - DSPP: Deep Shape and Pose Priors of Humans
PY - 2019
Y1 - 10 2019
SP - 1:1
EP - 1:6
DO - 10.1145/3359566.3360051
SN - 978-1-4503-6994-7
PB - ACM
ER -
Posters
Proceedings of the 2022 ACM SIGGRAPH Conference on Motion, Interaction and Games (MIG) Posters, 2022
Edmund J. C. Findlay, Haozheng Zhang, Ziyi Chang and Hubert P. H. Shum
Topics: Character Animation, Generative AI
Webpage Cite This Plain Text
author={Findlay, Edmund J. C. and Zhang, Haozheng and Chang, Ziyi and Shum, Hubert P. H.},
booktitle={Proceedings of the 2022 ACM SIGGRAPH Conference on Motion, Interaction and Games},
series={MIG '22},
title={Denoising Diffusion Probabilistic Models for Styled Walking Synthesis},
year={2022},
publisher={ACM},
Address={New York, NY, USA},
location={Guanajuato, Mexico},
}
AU - Findlay, Edmund J. C.
AU - Zhang, Haozheng
AU - Chang, Ziyi
AU - Shum, Hubert P. H.
T2 - Proceedings of the 2022 ACM SIGGRAPH Conference on Motion, Interaction and Games
TI - Denoising Diffusion Probabilistic Models for Styled Walking Synthesis
PY - 2022
PB - ACM
ER -
Proceedings of the 2019 ACM SIGGRAPH Conference on Motion, Interaction and Games (MIG) Posters, 2019
Naoki Nozawa, Hubert P. H. Shum, Edmond S. L. Ho and Shigeo Morishima
Topics: 3D Reconstruction, Surface Modelling, Artwork Analysis, Generative AI
Webpage Cite This Plain Text
author={Nozawa, Naoki and Shum, Hubert P. H. and Ho, Edmond S. L. and Morishima, Shigeo},
booktitle={Proceedings of the 2019 ACM SIGGRAPH Conference on Motion, Interaction and Games},
series={MIG '19},
title={3D Car Shape Reconstruction from a Single Sketch Image},
year={2019},
month={10},
pages={37:1--37:2},
numpages={2},
doi={10.1145/3359566.3364693},
isbn={978-1-4503-6994-7},
publisher={ACM},
Address={New York, NY, USA},
location={Newcastle upon Tyne, UK},
}
AU - Nozawa, Naoki
AU - Shum, Hubert P. H.
AU - Ho, Edmond S. L.
AU - Morishima, Shigeo
T2 - Proceedings of the 2019 ACM SIGGRAPH Conference on Motion, Interaction and Games
TI - 3D Car Shape Reconstruction from a Single Sketch Image
PY - 2019
Y1 - 10 2019
SP - 37:1
EP - 37:2
DO - 10.1145/3359566.3364693
SN - 978-1-4503-6994-7
PB - ACM
ER -
Proceedings of the 2019 ACM SIGGRAPH Conference on Motion, Interaction and Games (MIG) Posters, 2019
Jingtian Zhang, Hubert P. H. Shum, Kevin D. McCay and Edmond S. L. Ho
Topics: 3D Reconstruction, Surface Modelling, Generative AI
Webpage Cite This Plain Text
author={Zhang, Jingtian and Shum, Hubert P. H. and McCay, Kevin D. and Ho, Edmond S. L.},
booktitle={Proceedings of the 2019 ACM SIGGRAPH Conference on Motion, Interaction and Games},
series={MIG '19},
title={Prior-Less 3D Human Shape Reconstruction with an Earth Mover's Distance Informed CNN},
year={2019},
month={10},
pages={44:1--44:2},
numpages={2},
doi={10.1145/3359566.3364694},
isbn={978-1-4503-6994-7},
publisher={ACM},
Address={New York, NY, USA},
location={Newcastle upon Tyne, UK},
}
AU - Zhang, Jingtian
AU - Shum, Hubert P. H.
AU - McCay, Kevin D.
AU - Ho, Edmond S. L.
T2 - Proceedings of the 2019 ACM SIGGRAPH Conference on Motion, Interaction and Games
TI - Prior-Less 3D Human Shape Reconstruction with an Earth Mover's Distance Informed CNN
PY - 2019
Y1 - 10 2019
SP - 44:1
EP - 44:2
DO - 10.1145/3359566.3364694
SN - 978-1-4503-6994-7
PB - ACM
ER -